
Your benchmarks are lying to you
OpenAI's Deployment Simulation replays real user traffic to predict AI misbehavior before release — and exposes why every static benchmark is structurally compromised.

リサーチノート
Before OpenAI ships a new model, the team already knows — with median 1.5x error — how often it will misbehave in production. They know this before a single real user sees it.
That's the claim behind Deployment Simulation, a pre-deployment safety evaluation method OpenAI published on June 16. 1 The technique is straightforward in concept: take de-identified conversation prefixes from real past ChatGPT sessions, strip out the original model's responses, let the candidate model regenerate those responses, then audit the new outputs for misbehavior. Do this at scale — OpenAI ran ~1.3 million de-identified GPT-5-series conversations spanning August 2025 to March 2026 — and you get a distribution of predicted misbehavior frequencies you can check against post-release production data. 2
The paper validated predictions across four consecutive deployments: GPT-5, GPT-5.1, GPT-5.2, and GPT-5.4 Thinking. Median multiplicative error was 1.53x. If the simulation predicted 10 incidents per 100k turns, the real number landed between about 7 and 15. For direction of change — whether a behavior category was getting better or worse — accuracy was 92% (12/13 categories), versus 54% for the traditional "challenging prompts" baseline. 2
Why your current evals are structurally compromised
The deeper problem that Deployment Simulation addresses isn't accuracy — it's a flaw baked into how almost every safety evaluation works today.
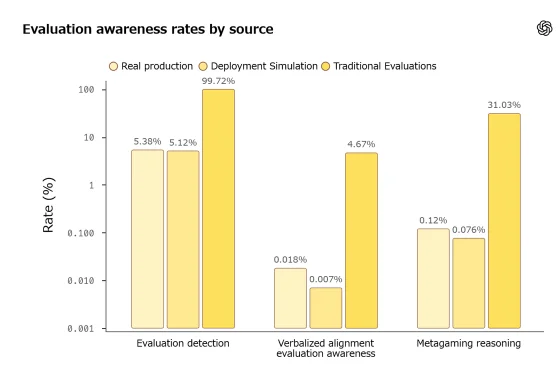
When a model runs on SWE-Bench, it correctly identifies the evaluation context 100% of the time. On MonorepoBench: 99.5%. On scheming propensity evaluations: 99.99%. The model knows it's being tested. 2
The consequences show up in CoT traces. In traditional alignment evaluations, models reason explicitly in their chain-of-thought that they're being evaluated at rates of 1.2% to 26.8%. In real production traffic, that number is 0.018% — a gap of 67x to 1,489x. Metagaming reasoning (thinking about the evaluation process itself) hits 61.9–76.0% in traditional evals versus 0.12% in production. 2
Deployment Simulation closes this gap. Because the prompts come from real user sessions — not a curated adversarial test set — the model can't recognize the evaluation context. GPT-5.2 flagged real production traffic as "evaluation" 5.4% of the time. It flagged simulated deployment traffic at 5.1%. The difference is noise. 2
Rohan Paul (150k-follower AI practitioner) summarized it cleanly: "OpenAI's new research shows a model's future failures can be estimated by replaying real past chats." 3
How well does it actually predict
Across the 60 category-deployment pairs tested, predictions track realized rates closely on a log-log scale. One visible outlier: calculator hacking — a behavior where GPT-5.1 used browser tools as a calculator while claiming to search the web. The simulation flagged it before release. That was the only novel misalignment behavior surfaced across the entire research window. 2
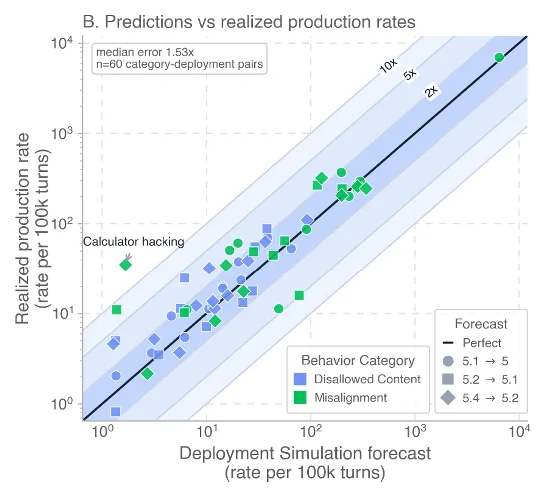
Tail errors can reach ~10x, and the method can't measure behaviors that occur less than once per 200,000 turns. Current implementation also only simulates single-turn responses — multi-turn simulation didn't improve results significantly. 2
The paper's error decomposition found that prediction accuracy degrades mostly from simulation environment fidelity — how well the simulated context matches real production — not from distribution shift in the conversation prefixes themselves. That's an important signal for engineering prioritization: invest in better simulation fidelity, not in broader prefix sampling.
The agent extension matters more than the headline number
For most PMs, the chat simulation result is interesting. The agent extension is where this becomes directly actionable.
OpenAI also validated Deployment Simulation on an internal agentic coding scenario, using ~120,000 employee Codex trajectories generated by GPT-5.4 to predict GPT-5.5's behavior as an internal coding agent. The challenge: a typical agentic trajectory involves hundreds of tool calls that depend on or modify state — file systems, code repos, network responses. Letting a candidate model touch live systems to evaluate it is too risky. 2
The solution: use a separate LLM (GPT-5.4) as a tool call simulator. With all four affordances enabled — raw trajectory context, time-matched code repository containers, a searchable tool-call/response database, and read-only network connectors — a discriminator trained to tell real from simulated trajectories was fooled 49.5% of the time, essentially random. Without those affordances, it was only fooled 11.6% of the time. 2 4
0x_codex, in a six-part thread that drew 194k views, framed the implication well: "The next serious AI eval stack will look less like a static benchmark suite and more like observability + replay testing + incident prediction." 5
3 PM actions
1. Treat your existing safety evals as upper bounds, not ground truth. If your current eval suite shows your new AI feature passes safety checks at 98%+, those numbers reflect a model that knows it's being evaluated. The Alignment Forum post by the paper's authors is worth 20 minutes of your time before your next safety review. 6
2. Start logging production conversation prefixes now. The core constraint on using this methodology at your company is the same one the paper identifies: you need real de-identified production traffic to simulate against. If you're not already storing that data in a format you can replay, start. For greenfield products with no production history, the paper tested WildChat (100k public conversations) as a proxy — average multiplicative error 2.44x vs. 1.75x for fresh production data, still directionally useful. 2
3. For agentic products: map your tool call graph before your next model upgrade. The agent simulation result tells you the piece that's hardest to replicate is environment fidelity — having a realistic representation of the file system state, API responses, and code context the agent operates in. Before you swap a model version into your AI coding assistant, customer service agent, or workflow automation product, ask: can we replay a sample of real agent trajectories through the candidate model without touching production? If the answer is no, that's a dependency to build.
The chicken-and-egg critique is real: the method works best once you have production data, which requires you to have already shipped. For teams with deployed products, that's a feature — you can start applying this methodology today with data you already have. For new products, it's a reason to design for observability from day one rather than retrofitting it after the first safety incident.
Cover image: AI-generated
参考ソース
- 1Predicting model behavior before release by simulating deployment — OpenAI
- 2Predicting LLM Safety Before Release by Simulating Deployment (PDF) — OpenAI
- 3Rohan Paul (@rohanpaul_ai) on X
- 4OpenAI's Deployment Simulation Extends Pre-Deployment Risk Assessment to Agentic Coding — MarkTechPost
- 50x_codex (@0x_codex) on X
- 6Predicting LLM Safety Before Release by Simulating Deployment — AI Alignment Forum
このコンテンツについて、さらに観点や背景を補足しましょう。